Prototyping a Recommender System for Binary Implicit Feedback Data with R and Keras
Ten years ago, the Netflix prize competition made a significant impact on recommender systems research. In the same time, such benchmark datasets, including MovieLens, are a bit misleading: in reality, implicit feedback data, or binary implicit feedback data (someone interacted with something) could be the best we can have. One to five star ratings type of continuous response data could be challenging to get or impossible to measure.

Photo: One in A Million by Veronica Benavides
To do collaborative filtering with such data is a curse because the 0-1 entries in the matrix we want to decompose has far less information than a 1 to 5 score. While it is also a blessing because a binary classification is usually easier to do, compared to a real-valued regression — the information we need from either the features or latent factors is less than what a regression model requires. So intuitively, it balances out.
Now I’ve got my new machine. I decided to rapidly build a prototype recommender system for binary implicit feedback data With R and Keras. The algorithm should be elementary to implement with the frameworks and directly trainable on CPU or GPU.
Poor Man’s Neural Collaborative Filtering
We will use the simple SVD idea popularized by the Netflix prize. Let’s say we have a m x n matrix R with binary values r_{ui}. We want to decompose it into a m x k matrix P and a k x n matrix Q with k latent factors each. The inner product p_u x q_i derived by latent representations p_u and q_i from P and Q will be used to predict r_{ui}. Everything is differentiable here so it can be optimized by gradient descent methods.
Some modifications for dealing with the binary implicit feedback data:
- Since
r_{ui}is binary (0-1 valued), we will use the binary cross entropy loss (commonly used for classification) instead of the regression-oriented MSE losses. - As a remedy for the sparsity (or unbalanced classes) often presented in matrix
R, we assign more weight to the less presented class (known interactions), which is necessarily “cost-sensitive learning”. Another possibility is to use random sampling to get different, much smaller sets of negative samples to balance the training data for each batch. - The inner product layer or the part before it is easily replaceable by arbitrary DNN architectures. I didn’t do it here though because I prefer to keep the model simple.
As a reference, what we are trying to do here is similar to what He et al. (WWW 2017) proposed, but even more straightforward. I call it “poor man’s neural collaborative filtering”.
Applications to Quantitative Systems Pharmacology
Let’s try this model with our data. The dataset is from a statistical methodology paper we published in 2015. It contains 746 drugs and 817 adverse drug reactions (ADRs), with 24,803 known drug-ADR associations. This data can be represented by a 746 x 817 matrix with 0-1 entries, where 1 denotes for having a known association. It’s implicit feedback: we don’t know any non-association drug-ADR pairs here, and all the missing drug-ADR pairs (all the pairs other than the known associated pairs) are marked as 0. We are interested in predicting if there are any novel associations between all the missing drug-ADR pairs. If successful, we will be able to forecast if a specific drug has any potential but unreported side effects, which helps the clinical pharmacology and pharmacovigilance practice.
For our data, the model parameters are summarized below (only 15k parameters, yay):
Code and Results
Let’s code it up with R + Keras and train it on GPU:
The key parameters to tune here are:
- The
optimizer. We chose RMSProp since it gave us the most stable training results. - The number of latent factors
k. We finally decided to use 5 because it is unlikely that one needs 50 factors to do this well. One probably also needs more layers for a largerk. - The
class_weight. We tried a few from 1:1 to 500:1 and finally selected the 50:1 ratio. - The
batch_size. Due to the sparsity of the matrix, this affects the performance.
The loss and accuracy changes in each epoch are visualized below:
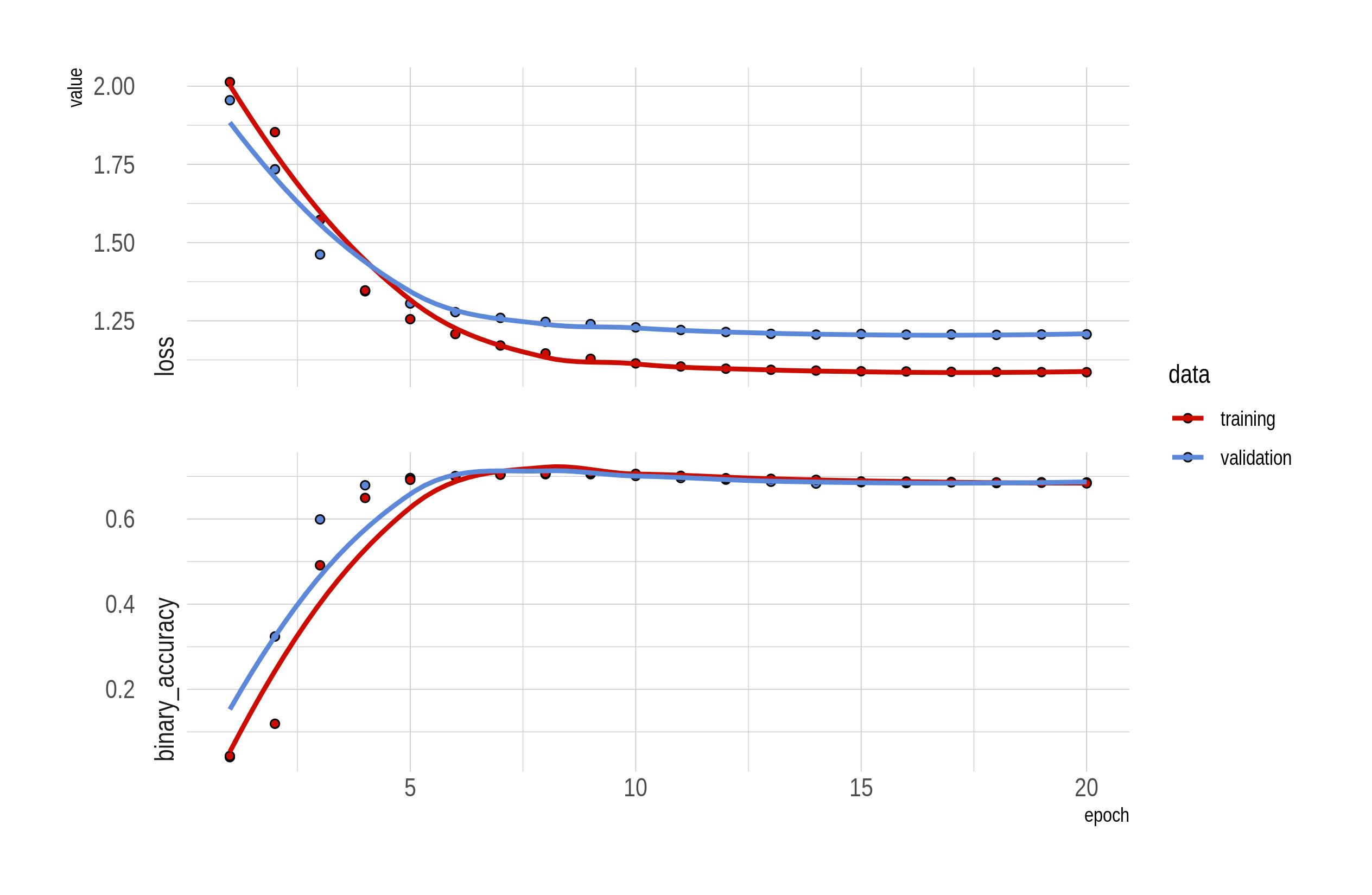
Figure: Converges within 10 epochs (after some slight tuning). The accuracy is around 0.7.
Comments
We have just prototyped a recommender system with only a few lines of R code, thanks to the flexibility offered by a modern machine learning framework with automatic differentiation and off-the-shelf optimizers. Two interesting topics to explore:
Here is the GitHub repo for the R code.