10 Things That Matter in Deep Learning (1/5)

Admit it or not, neural networks (or more broadly, connectionism) are being revived to readdress almost all problems in the machine learning world. Before deep learning, there were a few much smaller hypes like matrix factorization, sparse learning, and kernel methods, but none of them is comparable to this one. Never before has a learning method been so blessed by capital, yet so cursed by it.
This also means, despite the hype, deep learning did something right. Some particular components of this system are worth investigating. So, I decided to summarize some of the exciting parts of deep learning here and free these ideas from my mind.
This post will be the beginning of a five post series. The series will not try to be a comprehensive or even up-to-date overview of this topic. Instead, it serves as an opinionated record of the directions I think worth exploring in this field, according to my (limited) observations in the past five years. Note that a lot of the places in the DL land are still uncharted territories, so as usual, viewer discretion is advised.
1. Unified Learning Framework
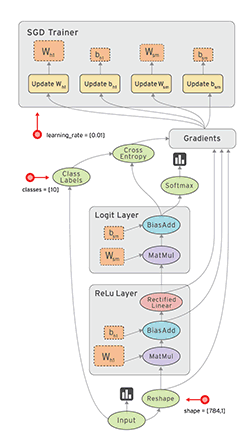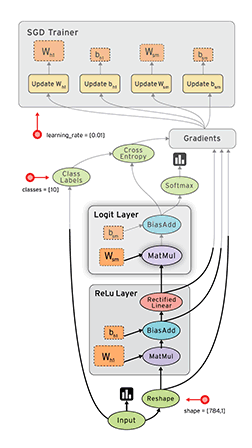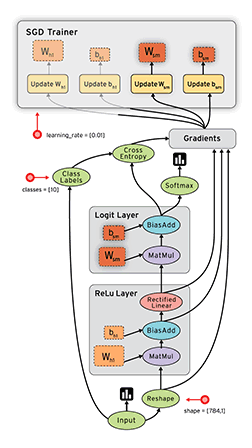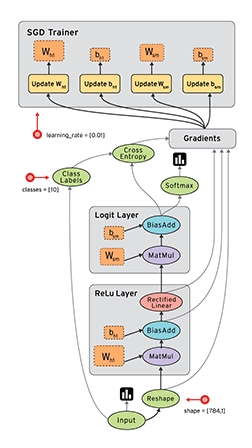
One framework to rule them all.
If there is only one thing that really matters in DL, this is it.
Deep learning offers a unified, scalable framework for large-scale machine learning modeling. You can simply formulate a machine learning problem as minimizing a loss function, reparameterize and replace the traditional components that connect the input and outcome with deep neural networks, then optimize the (differentiable) system with an off-the-shelve optimizer, most likely a derivative version of stochastic gradient descent (SGD).
A unified framework means it does not only work for traditional classification/regression problems. You can also apply this framework to directly optimize any adequately defined objective functions that used to be challenging to optimize or used to require customized solvers. For example, the well-known matrix factorization method in recommender systems, or the large margin nearest neighbor based triplet loss for supervised distance metric learning.
Such opportunities also created an invisible war for machine learning programming frameworks. Existing frameworks like TensorFlow, Keras, PyTorch, Caffe, MXNet, and many others could help people solve machine learning problems in a standardized fashion. Many interesting techniques also come with them. For instance, automatic differentiation is one of the key ingredients for such programming frameworks.
Having a good framework for doing things is critical. Like my friend Tao discussed (in Chinese), a good framework is not only useful for solving the problem itself, but also helps us better understand and fine-tune the system. Ultimately, a good framework will enable better communication and collaborative problem-solving.
2. Bayesian Deep Learning
Does the unified modeling framework idea sound familiar to you? Yes, everything described above is highly similar to what people can do in Bayesian modeling. We would first define a data model (prior + likelihood), then use MCMC/variational inference to optimize it (get the posterior). Several programming frameworks were also available.
Not surprisingly, the similarity inspired people to explore renovating traditional Bayesian models with the help of deep neural networks, or vice versa, integrating uncertainty and probabilistic inference into deep neural network structures for better interpretability. Such efforts can be categorized under the name “Bayesian deep learning.”
Bayesian deep learning can be useful in many scenarios requiring probabilistic inference. However, for some cases, especially in NLP applications, I doubt the models will have decent (predictive) performance gains by incorporating a DNN component, since many problems in text modeling are not as difficult as the problems in image recognition or speech recognition. As an example, there are some possibilities for doing “deep topic modeling,” but if I want to be more statistically rigorous, I would still prefer methods that do exact inference using MCMC. In the end, we would mostly expect such crossovers help improve the scalability or interpretability of the existing models.

Several probabilistic programming frameworks are being built for Bayesian deep learning (or just Bayesian modeling), including Edward, ZhuSuan, and greta. To some degree, they are very similar to Stan, whereas they took alternative approaches for optimization.
Next time, we will talk about feature learning and regularization.