Regularized Logistic Regressions with Computational Graphs
Nan Xiao <https://nanx.me>
Source:vignettes/logreg.Rmd
logreg.RmdIntroduction
The logreg package implemented logistic regression and regularized logistic regression models with the computational graph and automatic differentiation framework provided by the R package cgraph.
In this vignette, we will test the methods implemented in this package:
- Logistic regression
- Logistic regression with the ridge penalty (\(\ell_2\) regularization)
- Logistic regression with the seamless-\(\ell_0\) (SELO) penalty (differentiable approximation for \(\ell_0\) regularization)
We will also compare them with one existing method to make sure the data can be fitted by a reasonable regularized logistic regression model:
- Logistic regression with multi-step adaptive elastic-net (\(\ell_1\)-\(\ell_2\) based but approximately non-convex regularization)
Generate data
Let’s simulate some data for testing high-dimensional linear models:
sim <- msaenet.sim.binomial(
n = 500, p = 500, rho = 0.5, coef = rnorm(5, sd = 5), snr = 2,
p.train = 0.7, seed = 2019
)Now we have
- 350 samples in the training set and 150 in the test set;
- 500 variables with the first 5 of them being true variables;
- Moderate correlations between variables (
rho = 0.5) and moderate signal-to-noise ratio (snr = 2).
Fit the models
Fit the models on the training set:
fit_base <- fit_logistic(x = sim$x.tr, y = sim$y.tr, n_epochs = 500)
fit_ridge <- fit_logistic_ridge(x = sim$x.tr, y = sim$y.tr, n_epochs = 500, lambda = 0.5)
fit_selo <- fit_logistic_selo(x = sim$x.tr, y = sim$y.tr, n_epochs = 500, tau = 0.05)
fit_msaenet <- msaenet(sim$x.tr, sim$y.tr, family = "binomial", init = "ridge", tune = "ebic", nsteps = 10L, seed = 2009)Convergence
Plot the training errors vs. epochs:
par(mfrow = c(1, 3))
plot_error(fit_base)
plot_error(fit_ridge)
plot_error(fit_selo)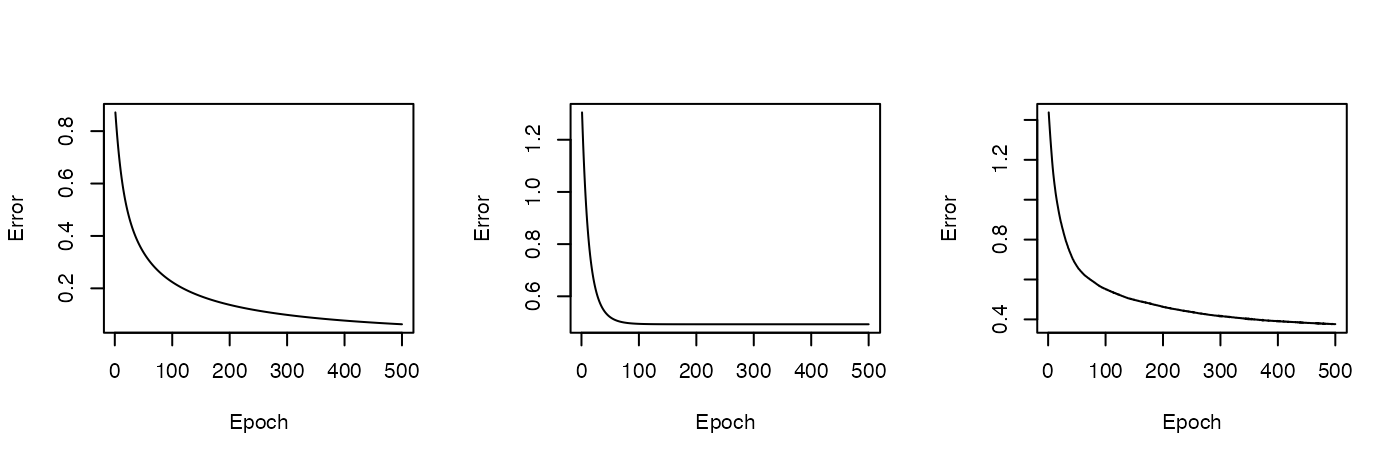
The ridge model converged around 100 epochs, much faster than the other two models (vanilla and SELO).
Estimated coefficients
Let’s plot the estimated coefficients and see if they meet our expectations.
The logistic regression got the overall correct estimation for true variables; other variables got smaller coefficients:
plot_coef(fit_base)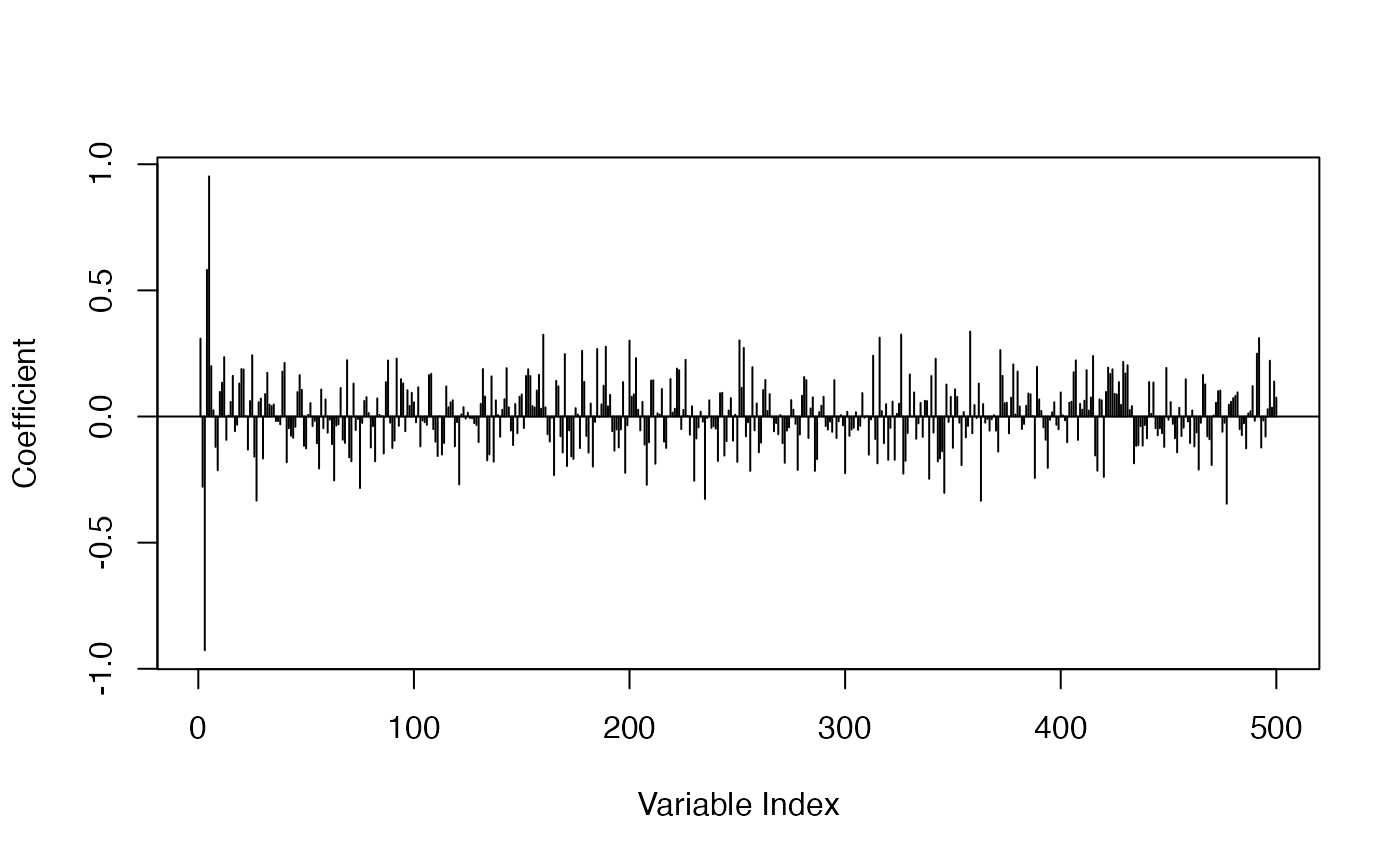
For the ridge model, some shrinkage effects are observed while no sparsity was induced, as expected:
plot_coef(fit_ridge)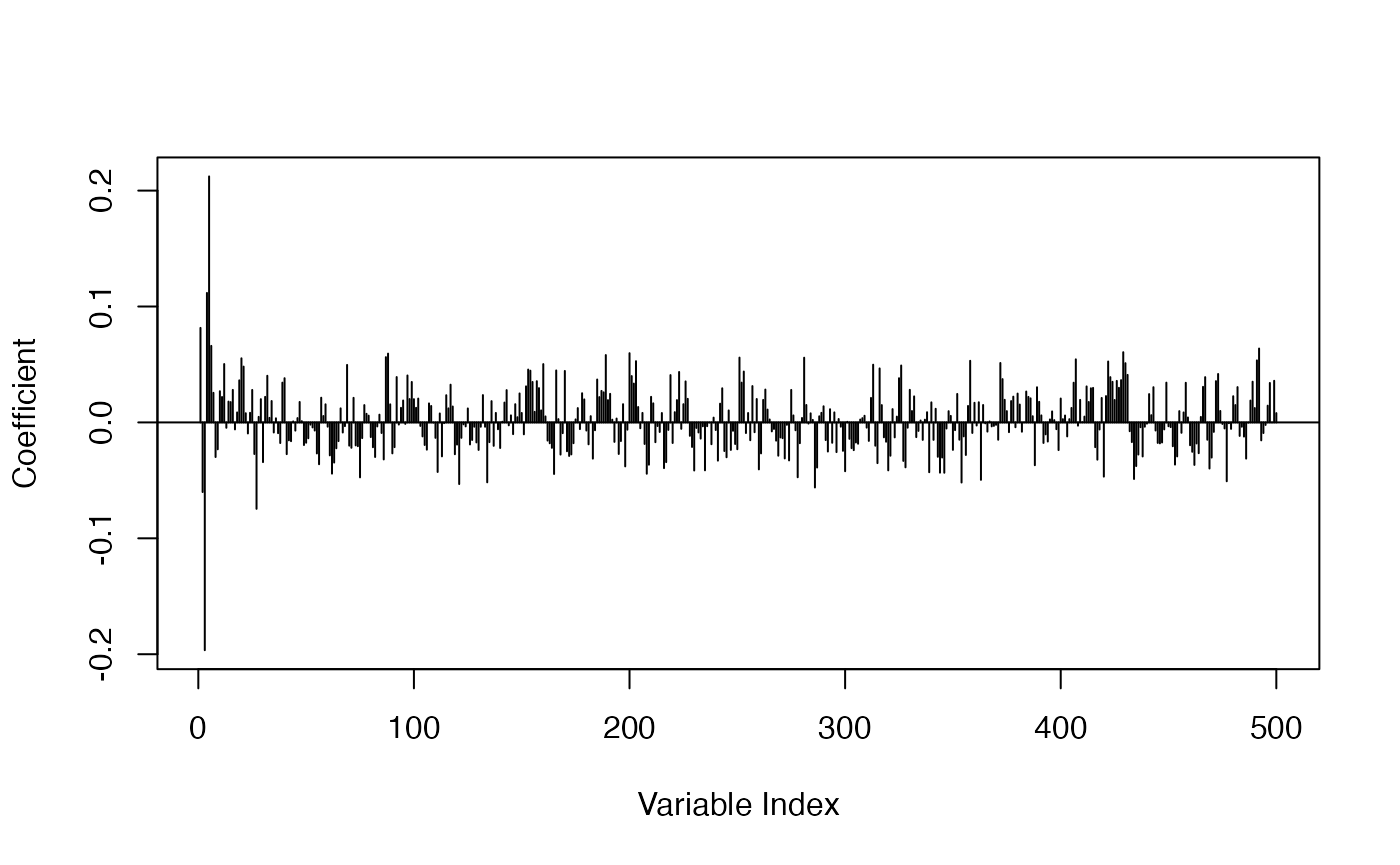
For the SELO model, we can see the shrinkage effect and apparent sparsity in the estimation results. Note that the near-zero coefficients are not estimated as precisely 0, due to the limitation of our unconstrained gradient-based optimization method.
plot_coef(fit_selo)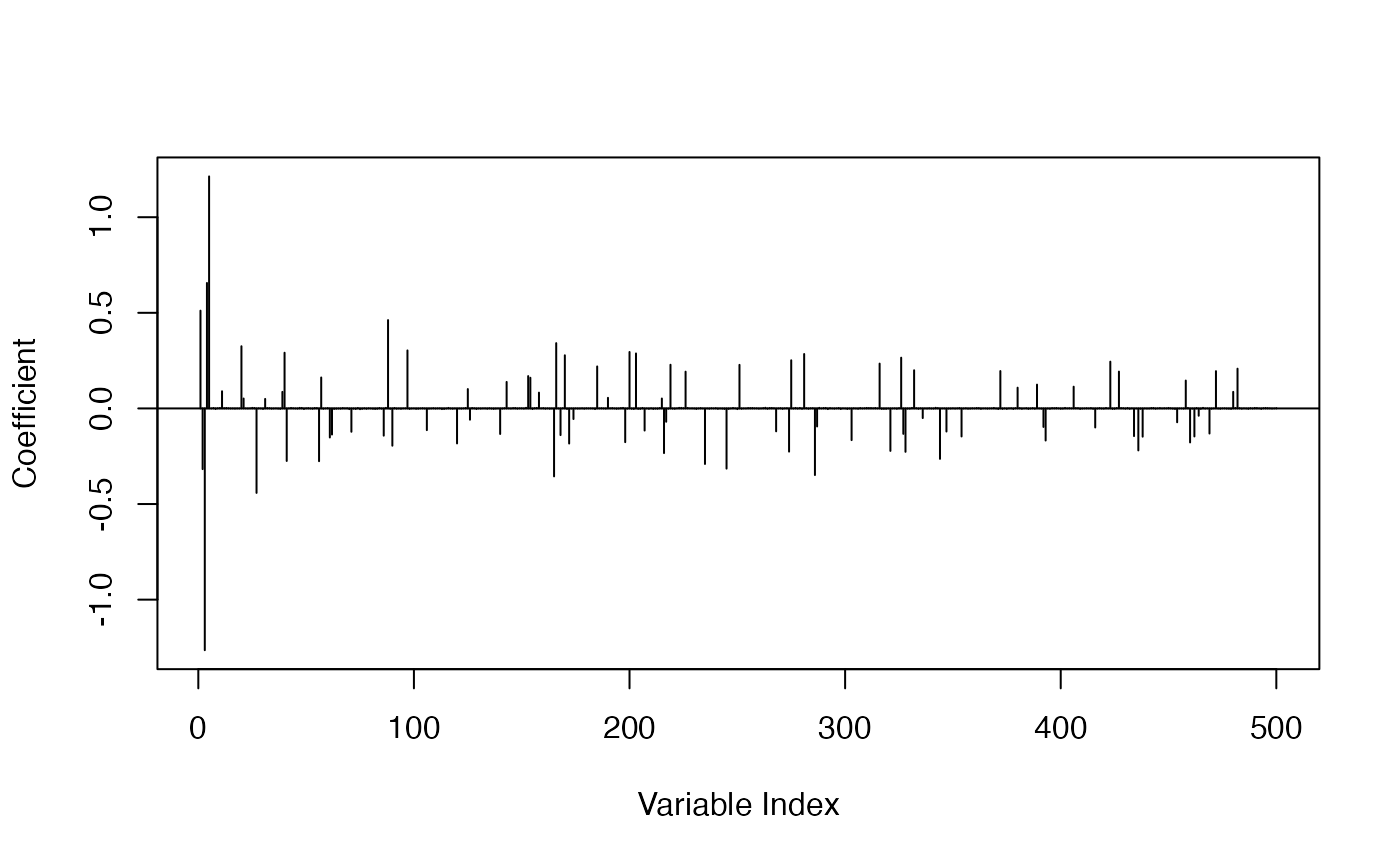
The multi-step adaptive elastic-net gave us a model closest to the true model, with 4 in 5 true variables estimated to be non-zero, with all others being 0 (1 false negative):
plot_coef(fit_msaenet)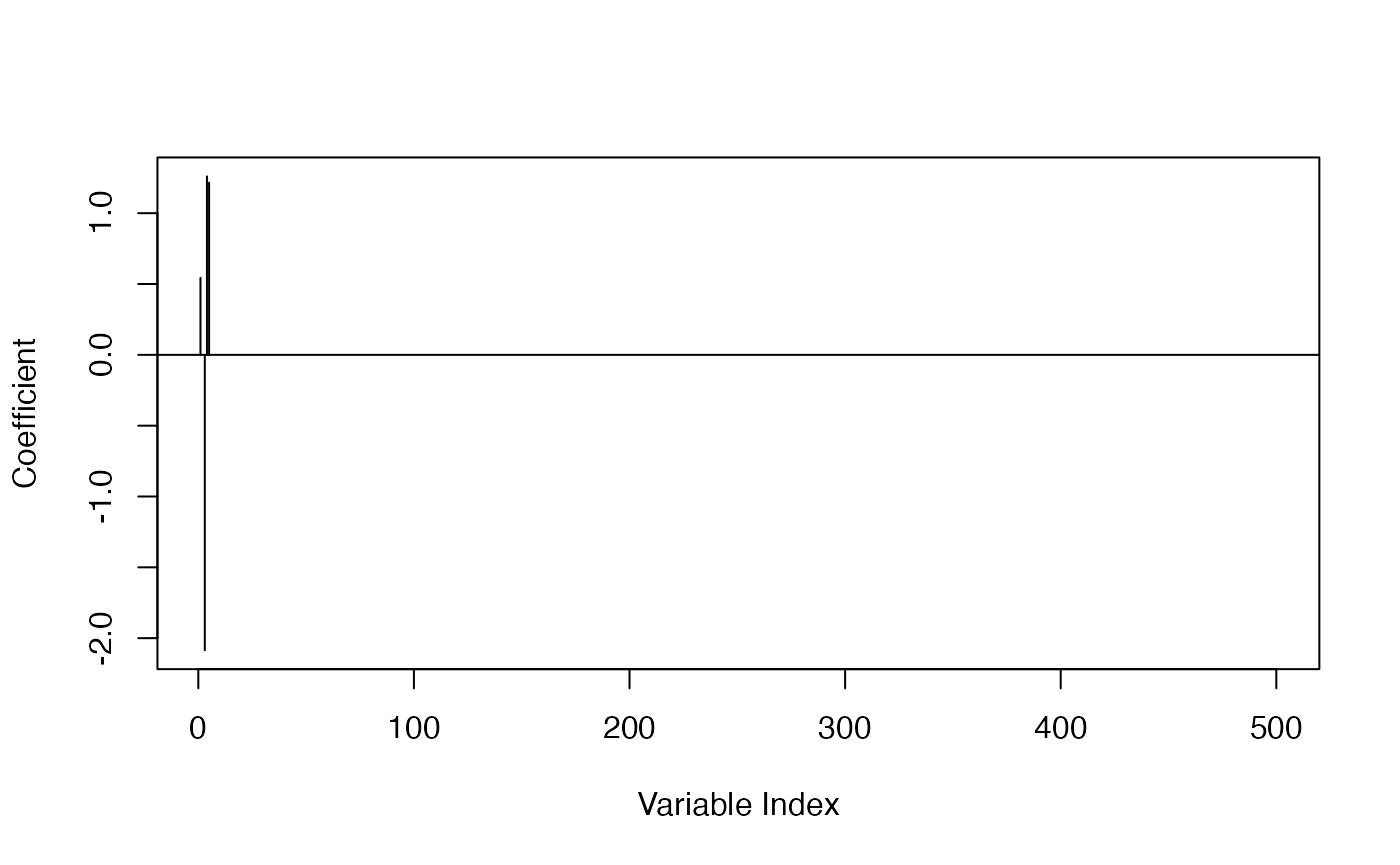
Predictive performance
Let’s compute AUC on the training and test set.
The logistic regression model sets the baseline, and overfits the training set:
c(auc(sim$y.tr, predict(fit_base, sim$x.tr)), auc(sim$y.te, predict(fit_base, sim$x.te)))
#> [1] 1.0000000 0.6626506The ridge model clearly overfits the training set too, but with 3% to 4% AUC improvement on the test set compared to the baseline:
c(auc(sim$y.tr, predict(fit_ridge, sim$x.tr)), auc(sim$y.te, predict(fit_ridge, sim$x.te)))
#> [1] 0.9923589 0.6951987The SELO model overfits the training set, with an almost 10% AUC improvement on the test set compared to the baseline:
c(auc(sim$y.tr, predict(fit_selo, sim$x.tr)), auc(sim$y.te, predict(fit_selo, sim$x.te)))
#> [1] 0.9912813 0.7574177The multi-step adaptive elastic-net model has similar AUCs over the training set and set set. with a 20% AUC improvement on the test set compared to the baseline: